
It’s models are literally open source.
People have this fear of trusting the Chinese government, and I get it, but that doesn’t make all of china bad. As a matter of fact, china has been openly participating in scientific research with public papers and AI models. They might have helped ChatGPT get to where it’s at.
Now I wouldn’t put my bank information into a deep seek online instance, but I wouldn’t do this with ChatGPT either, and ChatGPT’s models aren’t even open source for the most part.
I have more reasons to trust deep seek as opposed to chatgpt.
It’s just free, not open source. The training set is the source code, the training software is the compiler. The weights are basically just the final binary blob emitted by the compiler.
That’s wrong by programmer and data scientist standards.
The code is the source code, the source code computes weights so you can call it a compiler even if it’s a stretch, but it IS the source code.
The training set is the input data. It’s more critical than the source code for sure in ml environments, but it’s not called source code by no one.
The pretrained model is the output data.
Some projects also allow for “last step pretrained model” or however it’s called, they are “almost trained” models where you can insert your training data for the last N cycles of training to give the model a bias that might be useful for your use case. This is done heavily in image processing.
no, it’s not. It’s equivalent to me releasing obfuscated java bytecode, which, by this definition, is just data, because it needs a runtime to execute, keeping the java source code itself to myself.
Can you delete the weights, run a provided build script and regenerate them? No? then it’s not open source.
The model itself is not open source and I agree on that. Models don’t have source code however, just training data. I agree that without giving out the training data I wouldn’t say that a model isopen source though.
We mostly agree I was just irked with your semantics. Sorry of I was too pedantic.
Yeah. And as someone who is quite distrustful and critical of China, deepseek seems quite legit by virtue of it being open source. Hard to have nefarious motives when you can literally just download the whole model yourself
I got a distilled uncensored version running locally on my machine, and it seems to be doing alright
Where is an uncensored version? Can you ask it about politics?
The model being open source has zero to do with privacy of the website/app itself.
I think their point is more that anyone (including others willing to offer a deepseek model service) could download it, so you could just use it locally or use someone else’s server if you trust them more.
Where would one find such version?
it’s on huggingface, just like the base model.
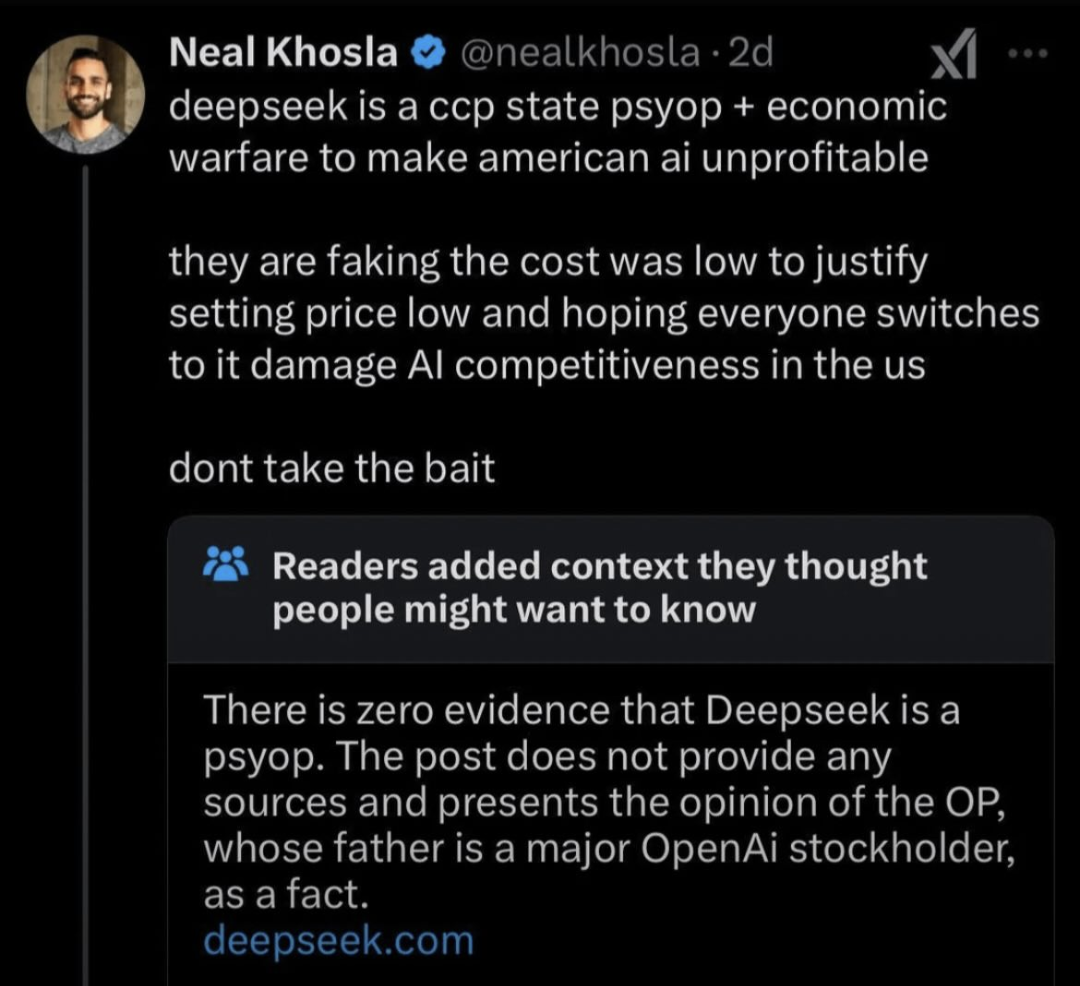
Also what’s more American than taking a loss to under cut competition and then hiking when everyone else goes out of business
to make american ai unprofitable
Lol! If somebody manage to divide the costs by 40 again, it may even become economically viable.
nO. STahP! yOUre doING ThE CApiLIsM wrONg! NOw I dONt liKE tHe FrEe MaKrET :(





{kind=link}